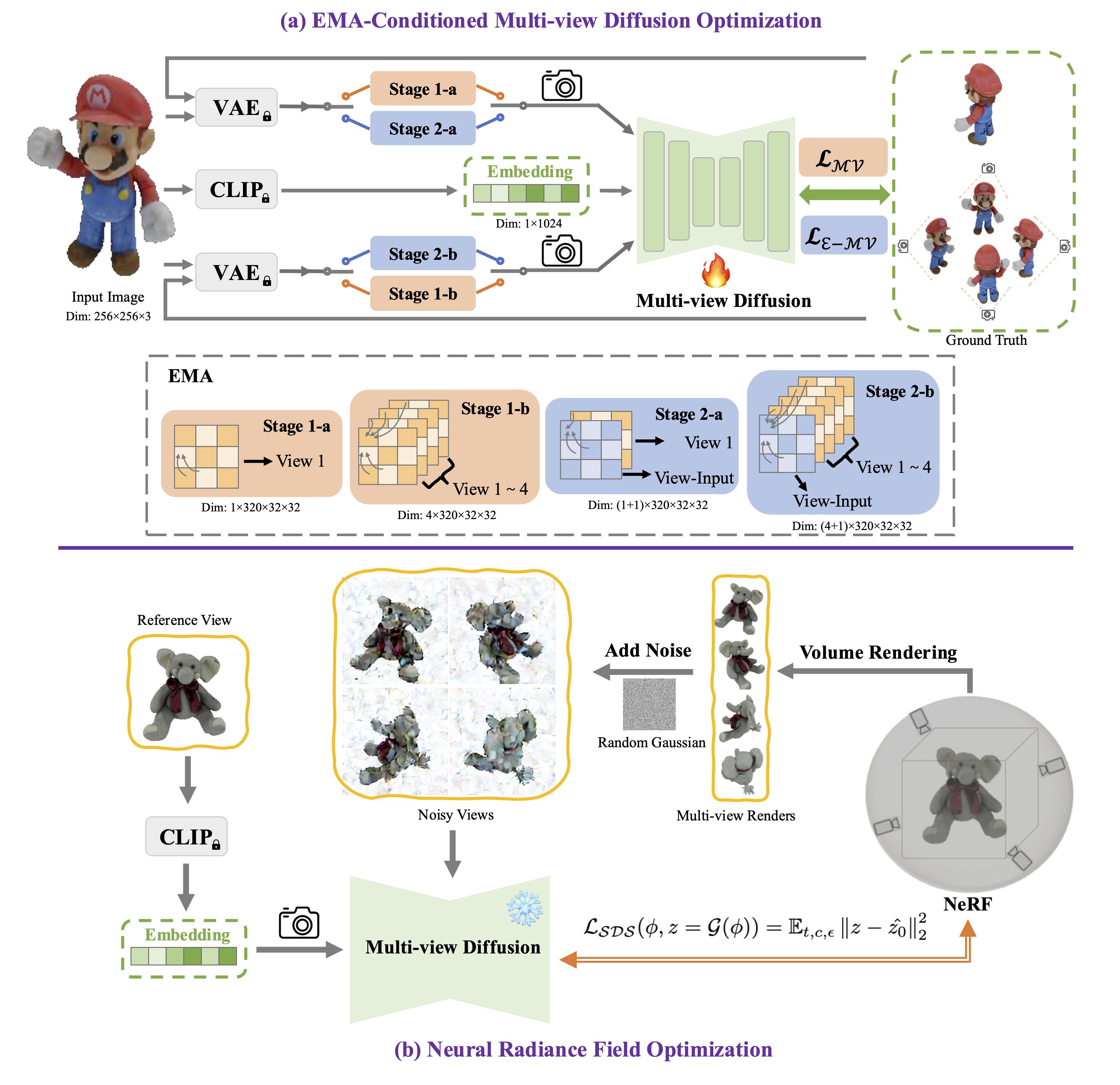
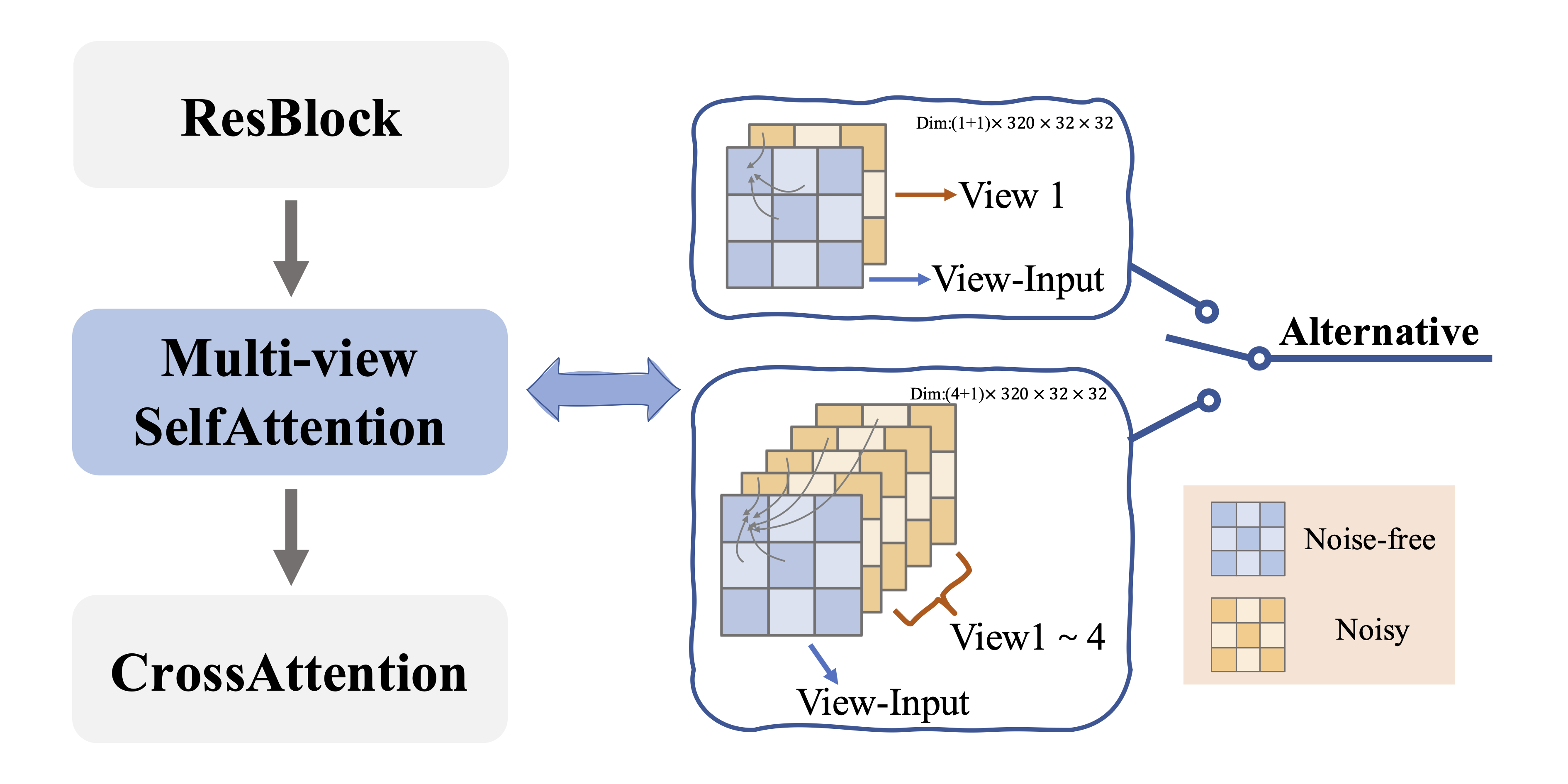
Encouraged by the growing availability of pre-trained 2D diffusion models, image-to-3D generation by leveraging Score Distillation Sampling (SDS) is making remarkable progress. However, most existing approaches rely heavily on reference-view image supervision, which often disrupts the inductive priors of diffusion models and leads to distorted geometry or overly smooth back regions. To overcome these limitations, we propose Isotropic3D, a novel image-to-3D framework that takes only a single image CLIP embedding as input. Our method ensures azimuth-angle isotropy by relying exclusively on the SDS loss, avoiding overfitting to the reference image. Isotropic3D is consist of two main components: a EMA-conditioned multi-view diffusion model (EMA-MVD) and a Neural Radiance Field (NeRF). The core of EMA-MVD lies in a two-stage fine-tuning. Firstly, we fine-tune a text-to-3D diffusion model by substituting its text encoder with an image encoder, by which the model preliminarily acquires image-to-image capabilities. Secondly, we perform fine-tuning using our Explicit Multi-view Attention (EMA), which combines noisy multi-view images with the noise-free reference image as an explicit condition. After fine-tuning, Isotropic3D, built upon SDS with NeRF, can generate multi-view consistent images from a single CLIP embedding and reconstruct a 3D model with improved symmetry, well-proportioned geometry, richly colored textures, and reduced distortion.