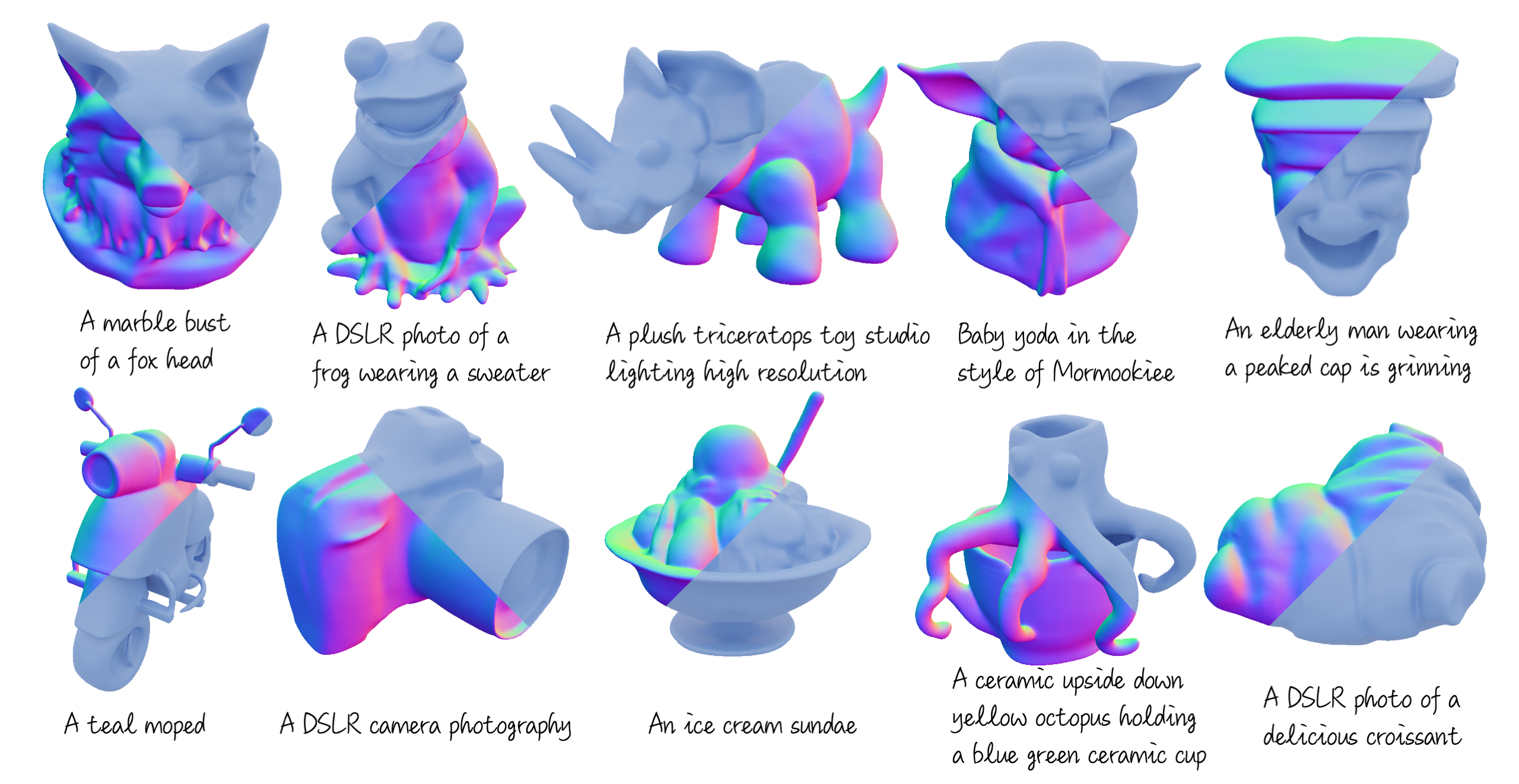
D3DM generates image-to-3D samples with impressive precision. Given a single-view image, it can produce fine-grained geometric details and high-quality 3D shapes within a matter of seconds.
Abstract
Diffusion Models have shown significant promise in generating high-fidelity 3D shapes from a single image. However, prior methods often suffer from a lack of fine-grained features, directional ambiguities and inconsistencies between the generated 3D shapes and the input images, which collectively undermine the overall controllability of the model. To address these challenges, we propose a Direct 3D Diffusion Model (D3DM) which consists of a Cross-modal Variational Auto-Encoder (CVAE) and an Image-conditioned 3D Latent Diffusion Model (I3D-LDM). CVAE encodes each shape into the latent space and decodes the latent to predict the occupancy values of the query points. It features three techniques: Normal Space Sampling (NSS), Rotation-Invariant (RI) and Shape-Image Cross-Modal Attention (SICA). NSS enhances the performance of the CVAE to capture fine details, particularly edges and sharp features. RI ensures directional consistency between the mesh and the image, while SICA dynamically fuses 3D features with 2D image information to improve the fine-grained geometory. The I3D-LDM generates the latent from a single image, utilizing a Pixel-Semantic Co-Guidance (PSC) mechanism to integrate global semantics from CLIP with pixel-level details from DINOv2, which ensures the generated 3D shapes exhibit both global semantic and pixel detail consistency. Extensive experiments demonstrate that D3DM is capable of generating high-fidelity 3D shapes with accurate directional consistency from a single-view image.
Method Overview
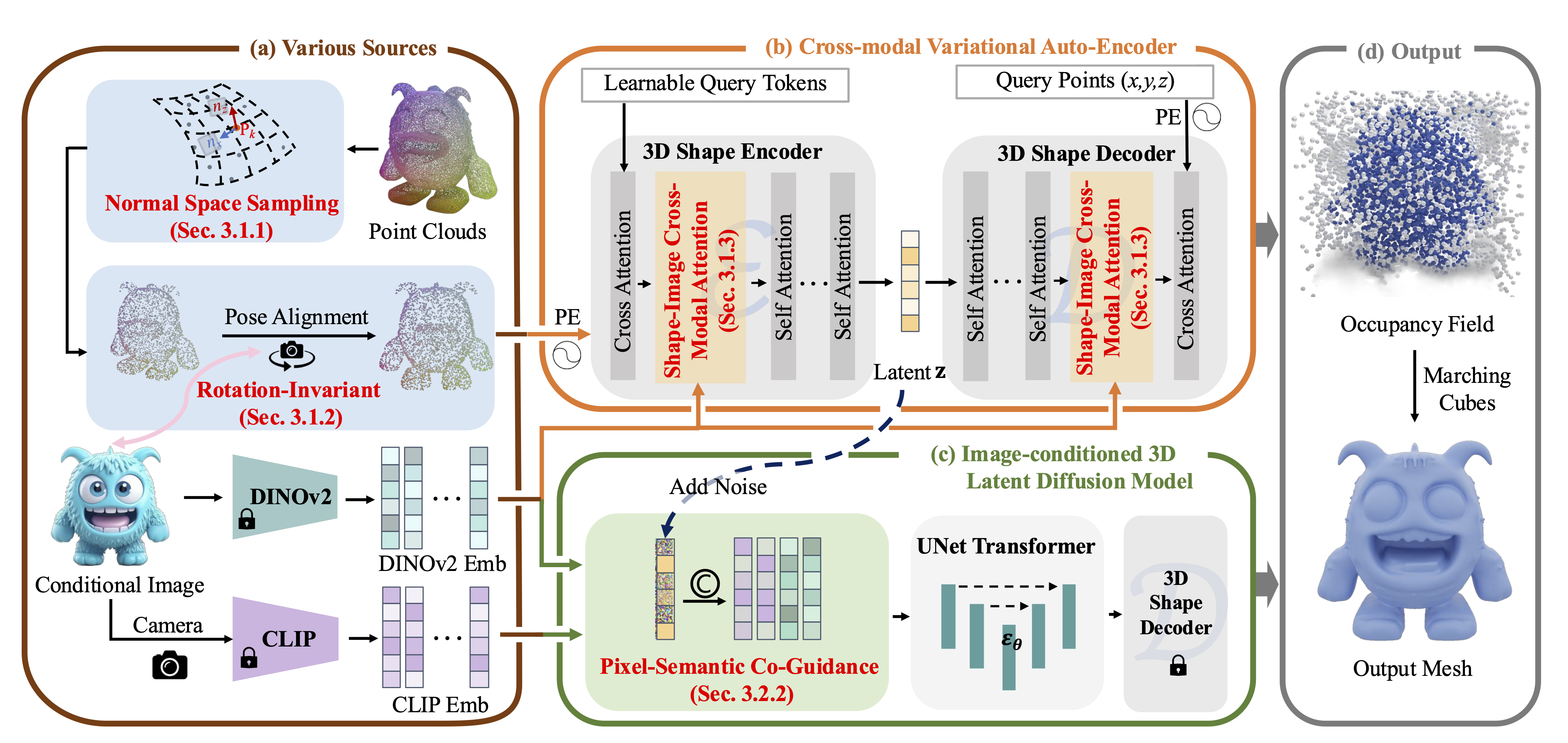
D3DM begins by training a Cross-modal Variational Autoencoder (CVAE) to encode each shape into a latent space, producing a shape latent embedding z. This embedding is then decoded to accurately predict the occupancy values for query points, enabling the generation of high-quality 3D shapes using the Marching Cubes algorithm. Building on the pre-trained CVAE, we develop a 3D latent diffusion model to learn the shape latent embedding from an input image. During inference, D3DM can generate high-quality 3D shapes from just a single image in a straightforward feed-forward process.
Qualitative comparisons
More image-to-3D results
Application: Text to 3D